ASCENDENT FEMALE BIAS
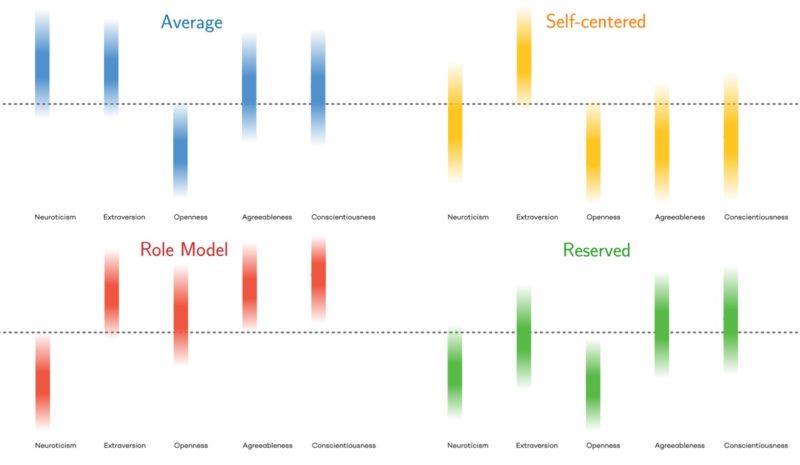
Average: These people score high in neuroticism and extraversion, but score low in openness. It is the most typical category, with women being more likely than men to fit into it.
ASCENDENT MALE BIAS
Self-Centered: These people score very high in extraversion, but score low in openness, agreeableness, and conscientiousness. Most teenage boys would fall into this category, according to Revelle, before (hopefully) maturing out of it. The number of people who fall into this category decreases dramatically with age.
ESTABLISHED FEMALE BIAS
Role Models: These people score high in every trait except neuroticism, and the likelihood that someone fits into this category increases dramatically as they age. “These are people who are dependable and open to new ideas,” says Amaral. “These are good people to be in charge of things.” Women are more likely than men to be role models.
ESTABLISHED MALE BIAS
Reserved: This type of person is stable emotionally without being especially open or neurotic. They tend to score lower on extraversion but tend to be somewhat agreeable and conscientious.
ABSTRACT
—“Understanding human personality has been a focus for philosophers and scientists for millennia1. It is now widely accepted that there are about five major personality domains that describe the personality profile of an individual2,3. In contrast to personality traits, the existence of personality types remains extremely controversial4. Despite the various purported personality types described in the literature, small sample sizes and the lack of reproducibility across data sets and methods have led to inconclusive results about personality types5,6. Here we develop an alternative approach to the identification of personality types, which we apply to four large data sets comprising more than 1.5 million participants. We find robust evidence for at least four distinct personality types, extending and refining previously suggested typologies. We show that these types appear as a small subset of a much more numerous set of spurious solutions in typical clustering approaches, highlighting principal limitations in the blind application of unsupervised machine learning methods to the analysis of big data.”—
https://www.nature.com/articles/s41562-018-0419-z